
Nesta postagem, falaremos como realizar a exportação de uma tabela que esteja no BigQuery para um bucket do Cloud Storage utilizando o Dataproc.

O que é BigQuery?
É um data warehouse totalmente gerenciado que permite realizar análises em um grande conjunto de dados, no patamar de petabytes.
Suporta consultas no formato ANSI SQL e criação de modelos de Machine Learning (ML) em uma sintaxe semelhante ao SQL.
O que é Cloud Storage?
Fornece, a nível mundial, um armazenamento de objetos altamente durável que escalona para exabytes de dados. É possível acessar dados instantaneamente de qualquer classe de armazenamento, integrar o armazenamento aos seus aplicativos com uma API exclusiva unificada e otimizar o preço e desempenho de forma fácil.
O que é Dataproc?
É a plataforma de big data totalmente gerenciado, para processar grandes quantidades de dados com rapidez, de forma econômica e em grande escala. Usando ferramentas de código aberto como o Apache Spark, o Apache Hive, o Apache Hadoop e o Apache Pig combinadas à escalabilidade dinâmica do Compute Engine e ao armazenamento escalável do Cloud Storage, o Dataproc oferece às equipes analíticas os mecanismos e a elasticidade para executar análises na escala de petabytes por uma fração do custo dos clusters locais tradicional, além de ser facilmente incorporado a outros serviços do Google Cloud Platform (GCP).
Passo a Passo
1. O primeiro passo a fazer é o login em sua conta do GCP, para este tutorial você vai precisar de uma conta que possua um projeto.
2. Vá até o console do BigQuery e crie um novo conjunto de dados:
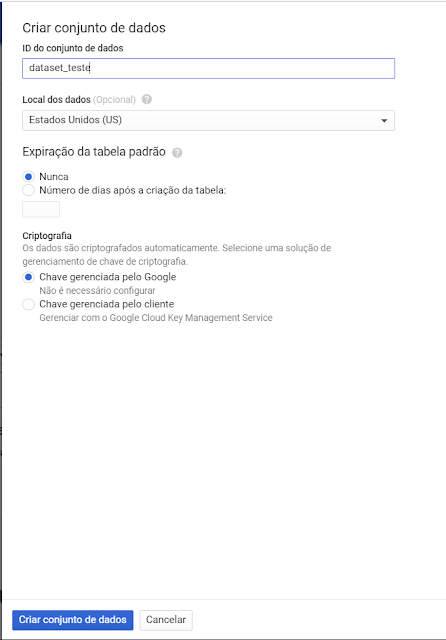
3. Insira um nome para o conjunto de dados e clique em criar:
4. Crie a tabela "clientes" a partir da query abaixo, vamos usar esses dados para fazer a exportação:
create table dataset_teste.clientes as
SELECT cliente_id, nome
FROM (
SELECT 1 AS cliente_id,'José' Nome UNION ALL
SELECT 2 AS cliente_id,'Maria' Nome UNION ALL
SELECT 3 AS cliente_id,'João' Nome UNION ALL
SELECT 4 AS cliente_id,'Pedro' Nome UNION ALL
SELECT 5 AS cliente_id,'Ana' Nome
) AS Clientes;5. Vá até a barra superior e clique no ícone do Cloud Shell, igual a imagem abaixo.

6. Criaremos o bucket do Cloud Storage em que iremos exportar nossa tabela:
gsutil mb -l us-central1 gs://[PROJECT_ID]-tabelas7. Agora temos que preparar as variáveis de ambiente que usaremos nos outros passos:
a) Para definir a variável de região usaremos o código abaixo:
export REGION=us-central1b) Para definir a variável de Zona usaremos o código abaixo:
export ZONE=us-central1-a8. Nesse passo vamos definir o projeto a ser usado dentro do cloud shell, no campo [PROJECT_ID], insira o id do seu projeto:
gcloud config set project [PROJECT_ID]9. Nesse passo vamos definir a Zona a ser usada dentro do cloud shell com base na variável que definimos antes:
gcloud config set compute/zone $ZONE10. Nesse passo vamos definir a Região a ser usada dentro do cloud shell com base na variável que definimos antes:
gcloud config set compute/region $REGION11. Após isso vamos definir a variável PROJECT com o id do projeto:
export PROJECT=$(gcloud info --format='value(config.project)')12. Com o código abaixo a api do dataproc será habilitada, caso já esteja pode desconsiderar:
gcloud services enable dataproc.googleapis.com sqladmin.googleapis.com13. Caso não exista, crie um cluster do dataproc com o comando abaixo:
gcloud dataproc clusters create meu-cluster \
--image-version 1.3 \
--region $REGION \
--subnet default \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 500 \
--num-workers 2 \
--worker-machine-type n1-standard-1 \
--worker-boot-disk-size 500Observações:
A propriedade “subnet” faz referência a sub-rede que usaremos no cluster.
A propriedade “master-machine-type” permite selecionar o tipo de máquina a ser usado pelo master.
A propriedade “worker-machine-type” permite selecionar o tipo de máquina a ser usado pelos workes.
14. Neste passo vamos gerar um job que vai criar uma tabela no hive:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "CREATE TABLE clientes \
(cliente_id string, \
nome string)\
ROW FORMAT DELIMITED \
FIELDS TERMINATED BY ',' \
STORED AS INPUTFORMAT \
'org.apache.hadoop.mapred.TextInputFormat' \
OUTPUTFORMAT \
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'\
LOCATION 'gs://[PROJECT_ID]-tabelas/clientes/'"Observações:
· A propriedade “submit” faz referência ao tipo de job que vamos executar, pode-se substituir o valor “hive” por “spark” ou “spark-sql” por exemplo.
· A propriedade “cluster” faz referência ao cluster que executaremos o job.
· A propriedade “region” faz referência a região em que o cluster está.
· A propriedade “execute” contêm o comando a ser executado, nesse caso a instrução de create.
15. Faça um select na tabela criada no passo anterior:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "select * from clientes"16. Realize um SSH na sua máquina do cluster, crie um arquivo chamado: bigquery-to-storage.py com o código abaixo, execute o código:
#!/usr/bin/python
from pyspark.sql import SparkSession
import pyspark
spark = SparkSession \
.builder \
.master('yarn') \
.appName('bigquery-to-cloud-storage') \
.getOrCreate()
#Usa o intervalo do Cloud Storage para exportação de dados temporários do BigQuery usados pelo conector.
bucket = "[PROJECT_ID]-tabelas"
spark.conf.set('temporaryGcsBucket', bucket)
# Lê os dados do BigQuery.
words = spark.read.format('bigquery') \
.option('table', '[PROJECT_ID]:dataset_teste.clientes') \
.load()
words.createOrReplaceTempView('cli')
#Gera arquivo no Cloud Storage
clientes_tb = spark.sql('SELECT * FROM cli')
clientes_tb.write.parquet('gs://[PROJECT_ID]-tabelas/clientes/clientes.parquet')17. Volte ao Cloud Shell e faça um select na tabela:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "select * from clientes"Referências
- Exporting table data
https://cloud.google.com/bigquery/docs/exporting-data#console
- Use the BigQuery connector with Spark
https://cloud.google.com/dataproc/docs/tutorials/bigquery-connector-spark-example





{kind=link}