
Nesta postagem, mostraremos como usar criar uma tabela externa do BigQuery a partir de uma tabela particionada no Hive, sendo que os dados estão armazenados no Cloud Storage.  |
O que é Cloud Dataproc?
É a plataforma de big data totalmente gerenciado, para processar grandes quantidades de dados com rapidez, de forma econômica e em grande escala. Usando ferramentas de código aberto como o Apache Spark, o Apache Hive, o Apache Hadoop e o Apache Pig combinadas à escalabilidade dinâmica do Compute Engine e ao armazenamento escalável do Cloud Storage, o Dataproc oferece às equipes analíticas os mecanismos e a elasticidade para executar análises na escala de petabytes por uma fração do custo dos clusters locais tradicional, além de ser facilmente incorporado a outros serviços do Google Cloud Platform (GCP), neste tutorial será usado para execução do Hive.
O que é Cloud Storage?
Fornece, a nível mundial, um armazenamento de objetos altamente durável que escalona para exabytes de dados. É possível acessar dados instantaneamente de qualquer classe de armazenamento, integrar o armazenamento aos seus aplicativos com uma API exclusiva unificada e otimizar o preço e desempenho de forma fácil, neste tutorial será usado para armazenamento de dados do Hive e origem de leitura da tabela externa do BigQuery.
O que é Apache Hive?
O Apache Hive permite a realizar consultas e analises nos dados que estejam hospedados no sistema de arquivos (HDFS) do Apache Hadoop.
Sendo considerado um Data Warehouse, ele oferece uma linguagem de consulta semelhante ao SQL, que se chama Hive Query Language, na sigla HQL ou HiveQL.
O Hive precisa de um database externo para guardar informações de seus metadados, como por exemplo, as estruturas de suas tabelas ou views. Geralmente os bancos MySQL e PostgreSQL são instalados no cluster para fazer esse armazenamento.
O que é BigQuery?
É um data warehouse totalmente gerenciado que permite realizar análises em um grande conjunto de dados, no patamar de petabytes.
Suporta consultas no formato ANSI SQL e criação de modelos de Machine Learning (ML) em uma sintaxe semelhante ao SQL.
O que são tabelas externas no BigQuery?
Em uma tabela externa os dados não estarão armazenados no BigQuery, mas podem ser consultados por ele.
Nessa abordagem somente os metadados são criados nele, ao consultar a tabela a fonte de dados externa que será consultada.
Atualmente, o BQ aceita essas fontes externas:
- Bigtable
- Cloud Storage
- Google Drive
- Cloud SQL (Beta)
Nos seguintes formatos:
- Avro
- CSV
- JSON
- ORC
- Parquet
Passo a Passo - Linha de comando
1. O primeiro passo a fazer é o login em sua conta do GCP, para este tutorial você vai precisar de uma conta que possua um projeto.

2. Vá até a barra superior e clique no ícone do Cloud Shell, igual a imagem abaixo.

3. Agora temos que preparar as variáveis de ambiente que usaremos nos outros passos:
a)Para definir a variável de região usaremos o código abaixo:
export REGION=us-central1
b)Para definir a variável de Zona usaremos o código abaixo:
export ZONE=us-central1-a
4. Nesse passo vamos definir o projeto a ser usado dentro do cloud shell, no campo [PROJECT_ID], insira o id do seu projeto:
gcloud config set project [PROJECT_ID]
5. Nesse passo vamos definir a Zona a ser usada dentro do cloud shell com base na variável que definimos antes:
gcloud config set compute/zone $ZONE
6. Nesse passo vamos definir a Região a ser usada dentro do cloud shell com base na variável que definimos antes:
gcloud config set compute/region $REGION
7. Após isso vamos definir a variável PROJECT com o id do projeto:
export PROJECT=$(gcloud info --format='value(config.project)')
8. Com o código abaixo a api do dataproc será habilitada, caso já esteja pode desconsiderar:
gcloud services enable dataproc.googleapis.com sqladmin.googleapis.com
9. Criaremos o bucket do Cloud Storage que será o repositório de dados do hive:
gsutil mb -l $REGION gs://$PROJECT-warehouse
10. Crie um cluster do dataproc com o comando abaixo:
gcloud dataproc clusters create meu-cluster \
--image-version 1.3 \
--region $REGION \
--subnet default \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 500 \
--num-workers 2 \
--worker-machine-type n1-standard-1 \
--worker-boot-disk-size 500
11. Neste passo vamos gerar um job do Dataproc que vai criar uma tabela externa do hive:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "CREATE EXTERNAL TABLE transactions \
(SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) \
STORED AS PARQUET LOCATION 'gs://$PROJECT-warehouse/datasets/transactions';"
·Podemos ver o resultado do Job através da linha de comando ou no pelo console do GCP.
12. Agora vamos gerar um job do Dataproc que vai consultar a tabela externa que criamos no passo anterior:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "select * from transactions;"
Observação: Também é possível criar os Jobs do Dataproc através do console do GCP.
13. A tabela vai estar vazia pois ainda não tem arquivos na pasta, para que a tabela tenha dados, vamos copiar um arquivo na nossa pasta do Cloud Storage:
gsutil cp gs://hive-solution/part-00000.parquet \
gs://$PROJECT-warehouse/datasets/transactions/part-00000.parquet
14. Execute novamente o job de select para visualizar os dados carregados:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "select * from transactions limit 10;"
O retorno deve ser semelhante ao abaixo:

15. Crie uma tabela semelhante a anterior, porem particionada por ano:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "CREATE TABLE transactions_partition \
(SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) \
partitioned by (ano STRING)\
STORED AS PARQUET LOCATION 'gs://$PROJECT-warehouse/datasets/transactions_partition';"
15. Carregue a nova tabela com os dados da primeira tabela:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict;\
insert into transactions_partition \
partition(ano) \
select SubmissionDate , TransactionAmount , TransactionType, SUBSTR(SubmissionDate,1,4) as ano from transactions;"
Observação: Dependendo de como o cluster estiver configurado o job poderia falhar devido uma propriedade de partições dinâmicas, por isso foi acrescentado no código o trecho: "SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict;".
16. Execute um job de select para visualizar os dados carregados:
gcloud dataproc jobs submit hive \
--cluster meu-cluster \
--region $REGION \
--execute "select * from transactions_partition limit 10;"
17. Verifique como ficou a pasta desta tabela no Cloud Storage:
gsutil ls gs://$PROJECT-warehouse/datasets/transactions_partition
Observação: O retorno deverá ser semelhante a este:
gs://virtual-dog-20-warehouse/datasets/transactions_partition/
gs://virtual-dog-20-warehouse/datasets/transactions_partition/ano=2017/
gs://virtual-dog-20-warehouse/datasets/transactions_partition/ano=2018/
18. Agora a partir dos arquivos desse diretório, vamos criar nossa tabela externa no BQ. Vá até o console do BigQuery e crie um novo conjunto de dados:

19. Insira um nome para o conjunto de dados e clique em criar:
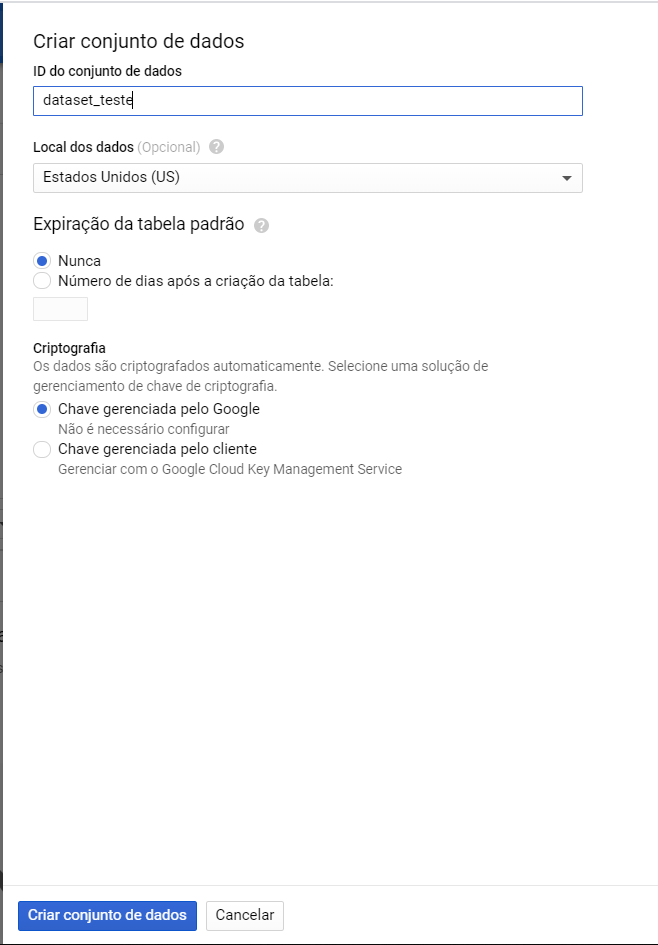
20. Clique em criar tabela e siga os passos abaixo:
- No campo "Criar tabela de:" selecione Google Cloud Storage;
- No campo "Selecionar arquivo do bucket do GCS:" insira o caminho da nossa tabela no cloud storage com asterisco (*) no final.
- Selecione o formato de arquivo como parquet.
- Marque a opção Particionamento de dados de origem.
- No campo "Selecione o prefixo do URI de origem:" insira o caminho da nossa tabela no cloud storage com gs:// no inicio.
- Insira um nome para sua tabela.
- Defina sua tabela como externa.
No final sua tela ficara semelhante a esta:

21. Faça um select na tabela criada:






{kind=link}